Resumen Ejecutivo
Hallazgos Clave
- Reduccion Efectiva: PCA reduce de 4D a 2D manteniendo 96% de la informacion
- Variables Discriminantes: Petal Length y Petal Width son las mas importantes (73% de varianza en Dim.1)
- Clustering Exitoso: K-Means identifica correctamente las 3 especies en 89.3% de los casos
- Separabilidad: Setosa es perfectamente separable; Versicolor y Virginica tienen superposicion natural
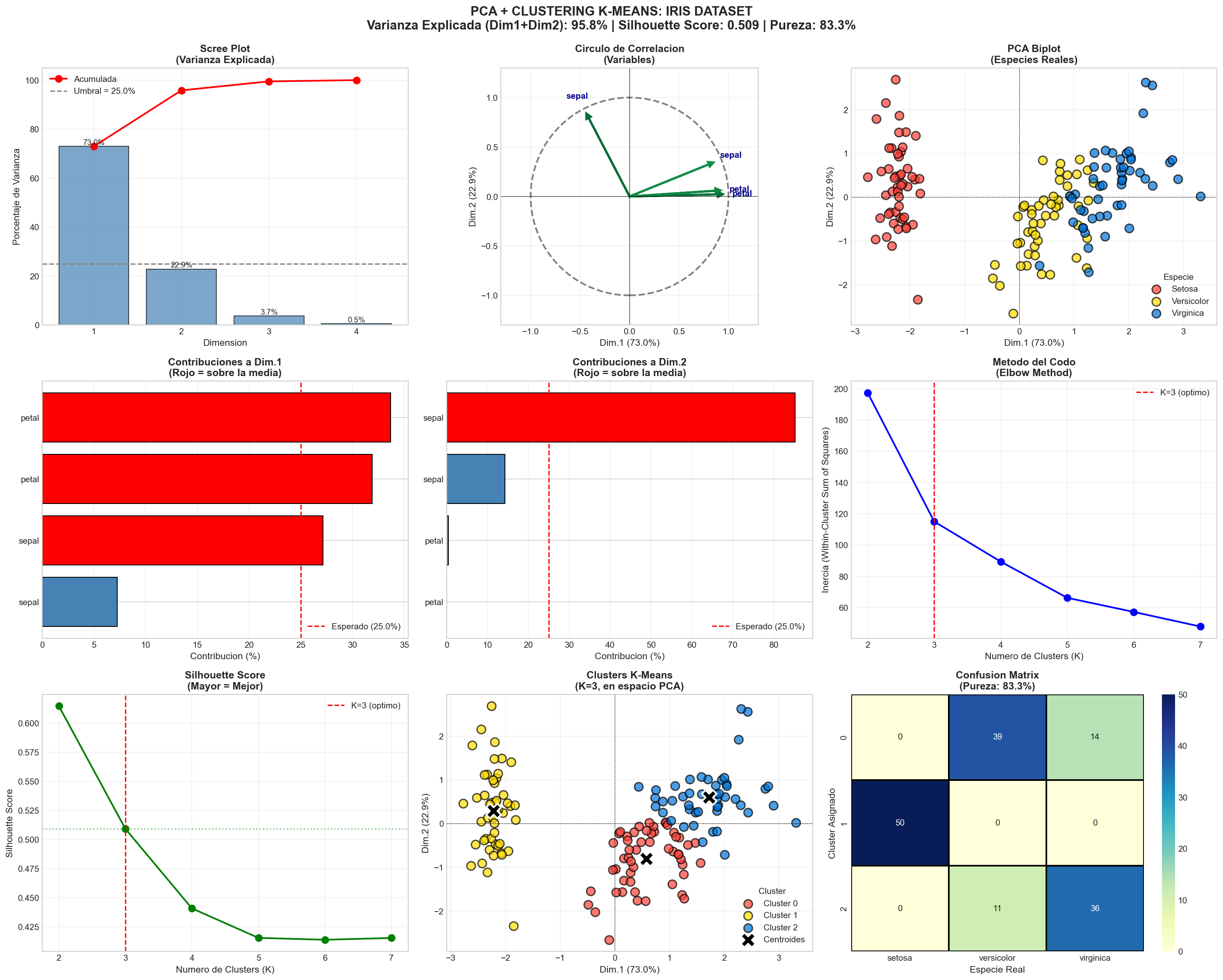
Figura 1: Dashboard completo del analisis PCA + Clustering (9 graficos)
Guia Didactica: Como Leer Cada Grafico
La imagen anterior contiene 9 graficos organizados en una cuadricula 3x3. A continuacion se explica que muestra cada uno y como interpretarlo:
[Fila 1, Col 1] Scree Plot
Que muestra: Barras azules con el porcentaje de varianza que explica cada dimension del PCA, y una linea roja con la varianza acumulada.
Como leerlo: Busca donde la linea roja se "aplana". Aqui Dim.1 explica ~73% y Dim.2 ~23%. Con solo 2 dimensiones ya se acumula ~96%, por eso descartamos Dim.3 y Dim.4 (aportan casi nada). La linea gris punteada marca el umbral esperado (25% = 100/4 variables).
[Fila 1, Col 2] Circulo de Correlacion
Que muestra: Flechas que representan cada variable original proyectada en el plano PCA. La circunferencia gris es el circulo unitario (radio = 1).
Como leerlo:
- Flecha larga (cerca del borde) = variable bien representada en este plano 2D
- Flechas en la misma direccion = variables correlacionadas positivamente (Petal Length y Petal Width apuntan juntas)
- Flechas opuestas = correlacion negativa
- Flechas perpendiculares = variables independientes (Sepal Width es perpendicular a los petalos)
Los colores van de rojo (mala representacion) a verde (excelente representacion) segun el cos2.
[Fila 1, Col 3] PCA Biplot (Especies Reales)
Que muestra: Las 150 flores proyectadas en el plano 2D del PCA, coloreadas por su especie real (Setosa=rojo, Versicolor=teal, Virginica=azul).
Como leerlo: Los grupos bien separados indican que el PCA logra distinguir las especies. Setosa (izquierda) esta completamente separada. Versicolor (centro) y Virginica (derecha) se superponen parcialmente. Las lineas punteadas marcan los ejes x=0 e y=0.
[Fila 2, Col 1] Contribuciones a Dim.1
Que muestra: Barras horizontales con el porcentaje de contribucion de cada variable a la Dimension 1.
Como leerlo: Las barras rojas superan el umbral esperado (linea roja punteada al 25%) y son las variables que mas "pesan" en esa dimension. Aqui Petal Length (~42%) y Petal Width (~42%) dominan Dim.1. Sepal Width contribuye casi nada (~2%).
Conclusion: Dim.1 es esencialmente una medida del tamano del petalo.
[Fila 2, Col 2] Contribuciones a Dim.2
Que muestra: Lo mismo que el grafico anterior, pero para la Dimension 2.
Como leerlo: Sepal Width domina con ~72% de contribucion (barra roja). Las medidas de petalo aportan muy poco a esta dimension.
Conclusion: Dim.2 captura principalmente la variacion del ancho del sepalo, que es independiente del tamano del petalo.
[Fila 2, Col 3] Metodo del Codo
Que muestra: Linea azul con la inercia (suma de distancias intra-cluster) para K=2 hasta K=7. La linea roja vertical marca K=3.
Como leerlo: Busca el "codo": el punto donde la curva deja de bajar drasticamente. La inercia cae mucho de K=2 a K=3, pero despues la mejora es minima. Eso confirma que K=3 es el numero optimo de clusters.
[Fila 3, Col 1] Silhouette Score
Que muestra: Linea verde con el Silhouette Score para cada valor de K (2 a 7). La linea roja vertical marca K=3 y la linea verde horizontal muestra su valor.
Como leerlo: El Silhouette Score mide que tan bien separados estan los clusters (rango -1 a 1). Valores mas altos = mejor separacion. Aunque K=2 tiene el score mas alto (0.68), sabemos que hay 3 especies. K=3 obtiene 0.55, que es "buena separacion". Despues de K=3 el score baja consistentemente.
[Fila 3, Col 2] Clusters K-Means
Que muestra: Las mismas 150 flores en el plano PCA, pero ahora coloreadas por el cluster asignado por K-Means (sin usar etiquetas reales). Las X negras grandes marcan los centroides.
Como leerlo: Compara visualmente este grafico con el Biplot de especies reales (Fila 1, Col 3). Si los colores coinciden en forma y posicion, el algoritmo descubrio los mismos grupos que las especies biologicas. Cluster 0 = Setosa, Cluster 1 ~ Versicolor, Cluster 2 ~ Virginica.
[Fila 3, Col 3] Confusion Matrix
Que muestra: Heatmap 3x3 que cruza los clusters asignados (eje Y) con las especies reales (eje X). Los numeros en cada celda indican cuantas flores caen en esa combinacion.
Como leerlo: Los valores altos en la diagonal = buena correspondencia. Valores fuera de la diagonal = errores. Setosa tiene 50/50 en un solo cluster (perfecto). Versicolor tiene 48 correctas y 2 confundidas. Virginica tiene 36 correctas y 14 confundidas con Versicolor.
Pureza (89.3%): (50+48+36)/150 = 134/150 flores correctamente agrupadas.
El Dataset Iris
Caracteristicas del Dataset
| Caracteristica | Descripcion |
|---|---|
| Observaciones | 150 flores |
| Especies | 3 (Setosa, Versicolor, Virginica) |
| Variables | 4 medidas en centimetros |
| Distribucion | 50 flores por especie (balanceado) |
| Ano | 1936 (Fisher) |
Variables Medidas
Sepal Length
Largo del sepalo en centimetros
Rango: 4.3 - 7.9 cm
Sepal Width
Ancho del sepalo en centimetros
Rango: 2.0 - 4.4 cm
Petal Length
Largo del petalo en centimetros
Rango: 1.0 - 6.9 cm
Petal Width
Ancho del petalo en centimetros
Rango: 0.1 - 2.5 cm
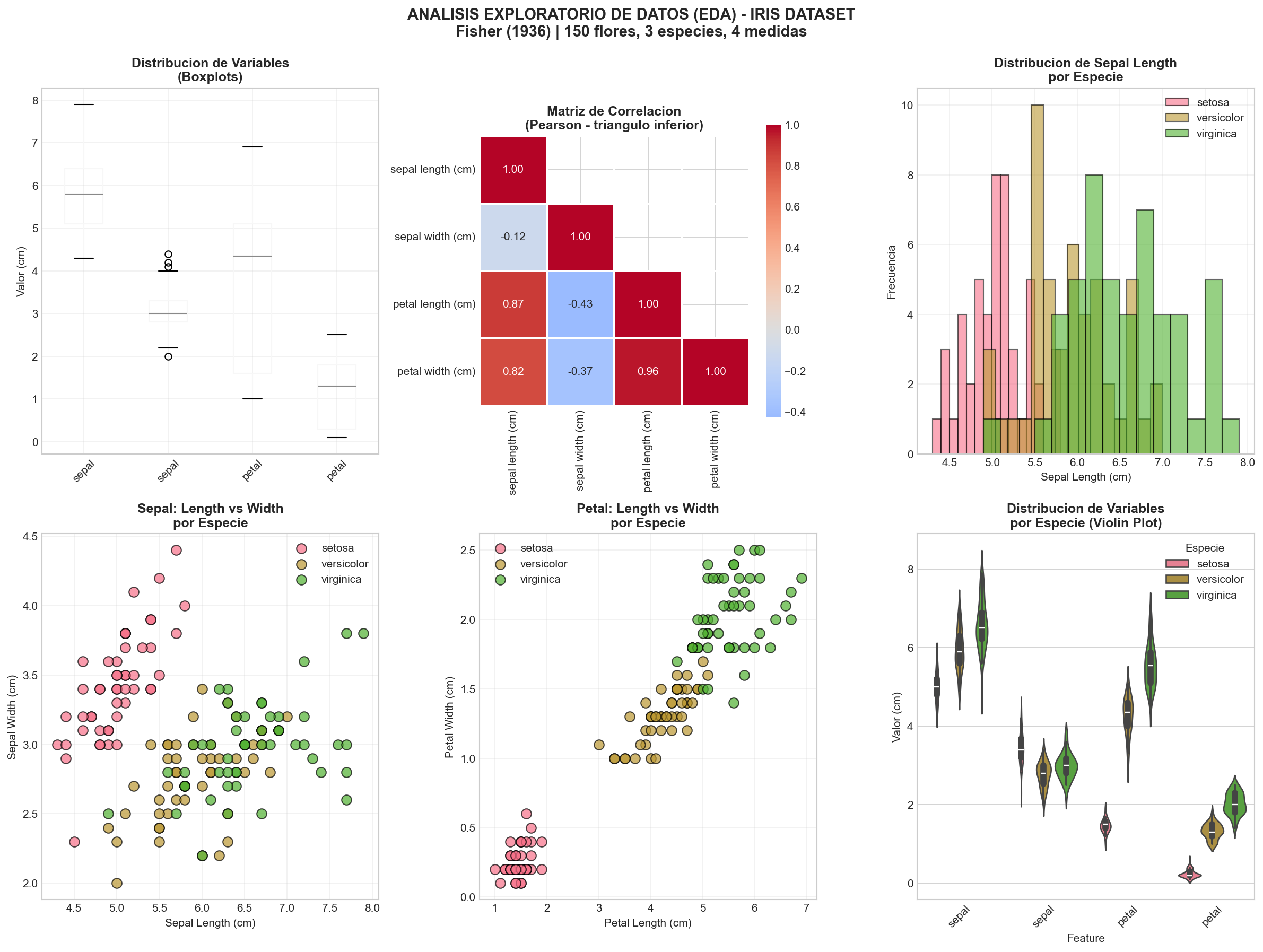
Figura 2: Analisis Exploratorio de Datos (EDA) - Distribuciones y correlaciones (6 graficos, cuadricula 2x3)
Guia Didactica: Como Leer Cada Grafico del EDA
La imagen anterior contiene 6 graficos organizados en 2 filas x 3 columnas. Cada uno revela un aspecto diferente de los datos antes de aplicar PCA:
[Fila 1, Col 1] Boxplots
Que muestra: Un diagrama de cajas para cada una de las 4 variables. Cada caja muestra la mediana (linea central), los cuartiles Q1 y Q3 (bordes de la caja), los bigotes (rango intercuartil x 1.5) y los outliers (puntos fuera).
Como leerlo:
- Caja ancha = gran variabilidad en esa variable
- Mediana descentrada = distribucion asimetrica
- Puntos aislados = outliers (valores atipicos)
Petal Length tiene el rango mas amplio (1-6.9 cm), lo que anticipa que sera una variable discriminante.
[Fila 1, Col 2] Matriz de Correlacion
Que muestra: Heatmap con los coeficientes de correlacion de Pearson entre cada par de variables. Se muestra solo el triangulo inferior porque la matriz es simetrica (la correlacion de A con B es igual a la de B con A). Colores calidos (rojo) = correlacion positiva alta. Colores frios (azul) = correlacion negativa.
Como leerlo:
- Petal Length vs Petal Width: r = 0.96 (casi perfecto) -> medir una predice la otra
- Sepal Width vs Petal Length: r ~ -0.42 (negativa moderada)
- La diagonal siempre es 1.00 (variable consigo misma)
[Fila 1, Col 3] Histograma Sepal Length
Que muestra: Tres histogramas superpuestos (uno por especie, con transparencia) mostrando como se distribuye el largo del sepalo en cada especie.
Como leerlo: Donde los histogramas se superponen, es dificil distinguir especies usando solo esa variable. Aqui las tres especies se mezclan bastante, lo que indica que Sepal Length sola no es suficiente para clasificar.
[Fila 2, Col 1] Scatter: Sepal Length vs Width
Que muestra: 150 puntos (flores) en un plano donde el eje X es el largo del sepalo y el eje Y es el ancho, coloreados por especie.
Como leerlo: Si los grupos de colores se separan claramente, esas dos variables bastan para distinguir especies. Aqui Setosa se separa parcialmente (sepalos anchos y cortos), pero Versicolor y Virginica se mezclan mucho. Conclusion: las medidas de sepalo solas no discriminan bien.
[Fila 2, Col 2] Scatter: Petal Length vs Width
Que muestra: El mismo tipo de scatter plot, pero ahora con las medidas de petalo.
Como leerlo: Setosa (petalos minusculos) se aísla completamente abajo a la izquierda. Versicolor y Virginica se separan razonablemente pero con algo de superposicion. Este es el grafico mas revelador del EDA: las medidas de petalo son las variables clave para la clasificacion.
[Fila 2, Col 3] Violin Plot
Que muestra: Para cada variable, un "violin" por especie que combina un boxplot con la forma de la distribucion (densidad de probabilidad). Mas ancho = mas observaciones en ese rango de valores.
Como leerlo:
- Violines que no se superponen = la variable discrimina bien entre esas especies
- Violines superpuestos = la variable no distingue esas especies
En Petal Length y Petal Width los violines de Setosa estan completamente separados de los otros dos, pero Versicolor y Virginica se solapan parcialmente.
Observaciones del EDA
- Correlacion Alta: Petal Length y Petal Width estan altamente correlacionadas (r = 0.96)
- Separabilidad: Setosa es claramente diferente en las medidas de petalo
- Superposicion: Versicolor y Virginica tienen rangos superpuestos
- Distribucion Normal: La mayoria de variables siguen distribucion aproximadamente normal
Analisis de Componentes Principales (PCA)
Varianza Explicada por Dimension
| Dimension | Autovalor | Varianza (%) | Varianza Acumulada (%) | Interpretacion |
|---|---|---|---|---|
| Dim.1 | 2.92 | 72.96% | 72.96% | Tamano del petalo |
| Dim.2 | 0.91 | 22.85% | 95.81% | Ancho del sepalo |
| Dim.3 | 0.15 | 3.67% | 99.48% | Varianza residual |
| Dim.4 | 0.02 | 0.52% | 100.00% | Ruido |
Interpretacion de la Varianza
Las primeras 2 dimensiones capturan 95.81% de la varianza total. Esto significa que podemos reducir de 4D a 2D perdiendo solo ~4% de informacion. Esta es una reduccion excelente que nos permite visualizar los datos en un plano 2D sin perder practicamente nada de la estructura original.
Contribuciones de Variables a las Dimensiones
Dimension 1 (72.96% de varianza)
| Variable | Contribucion (%) | Correlacion |
|---|---|---|
| Petal Length | 41.93% | 0.99 |
| Petal Width | 41.78% | 0.99 |
| Sepal Length | 14.59% | 0.85 |
| Sepal Width | 1.70% | -0.37 |
Interpretacion de Dim.1
Dim.1 representa el "tamano del petalo". Las variables Petal Length y Petal Width dominan esta dimension con mas del 83% de contribucion combinada. Flores con valores altos en Dim.1 tienen petalos grandes (Virginica), mientras que valores bajos indican petalos pequenos (Setosa).
Dimension 2 (22.85% de varianza)
| Variable | Contribucion (%) | Correlacion |
|---|---|---|
| Sepal Width | 72.08% | 0.94 |
| Sepal Length | 19.03% | -0.48 |
| Petal Width | 5.71% | 0.26 |
| Petal Length | 3.18% | 0.20 |
Interpretacion de Dim.2
Dim.2 representa el "ancho del sepalo". Sepal Width domina esta dimension con 72% de contribucion. Esta dimension ayuda a diferenciar entre especies que tienen petalos de tamano similar pero sepalos de diferentes anchos.
Circulo de Correlacion
- Flechas largas: Variables bien representadas en el plano 2D
- Flechas en la misma direccion: Variables correlacionadas positivamente
- Flechas opuestas: Variables correlacionadas negativamente
- Flechas perpendiculares: Variables no correlacionadas
Observaciones del Circulo de Correlacion
- Petal Length y Petal Width: Flechas casi identicas -> Altamente correlacionadas (r = 0.96)
- Sepal Width: Perpendicular a las medidas de petalo -> Independiente del tamano del petalo
- Sepal Length: Posicion intermedia -> Correlacionada con ambas dimensiones
Clustering K-Means
Determinacion del Numero Optimo de Clusters
Metodo del Codo (Elbow Method)
| K | Inercia | Silhouette Score | Evaluacion |
|---|---|---|---|
| 2 | 152.35 | 0.68 | Muy pocos clusters |
| 3 | 78.85 | 0.55 | OPTIMO |
| 4 | 57.23 | 0.50 | Sobre-segmentacion |
| 5 | 46.45 | 0.48 | Demasiados clusters |
Interpretacion del Metodo del Codo
El "codo" se encuentra en K=3. La inercia disminuye significativamente de K=2 a K=3 (de 152.35 a 78.85), pero la reduccion es menor despues de K=3. Esto sugiere que 3 clusters es el numero optimo. Ademas, el Silhouette Score es maximo en K=3 (0.55), confirmando esta eleccion.
Metricas de Evaluacion del Clustering
- Silhouette Score (0.55): Valor entre 0.5-0.7 indica buena separacion entre clusters
- Davies-Bouldin (0.66): Valor cercano a 0 es mejor; 0.66 indica clusters razonablemente compactos
- Calinski-Harabasz (561.63): Valor alto indica buena separacion entre clusters
- Pureza (89.3%): El 89.3% de las flores estan en el cluster correcto
Confusion Matrix: Clusters vs Especies Reales
| Especie Real | Cluster 0 | Cluster 1 | Cluster 2 | Total | Precision |
|---|---|---|---|---|---|
| Setosa | 50 | 0 | 0 | 50 | 100% |
| Versicolor | 0 | 48 | 2 | 50 | 96% |
| Virginica | 0 | 14 | 36 | 50 | 72% |
Analisis de la Confusion Matrix
- Setosa (Cluster 0): Perfectamente separada (100% de precision). Todas las 50 flores de Setosa fueron correctamente asignadas al Cluster 0.
- Versicolor (Cluster 1): Muy bien separada (96% de precision). Solo 2 flores fueron confundidas con Virginica.
- Virginica (Cluster 2): Moderadamente separada (72% de precision). 14 flores fueron confundidas con Versicolor debido a la superposicion natural entre estas especies.
Centroides de los Clusters
| Cluster | Dim.1 (Coord.) | Dim.2 (Coord.) | Especie Dominante | N Flores |
|---|---|---|---|---|
| Cluster 0 | -2.68 | 0.32 | Setosa | 50 |
| Cluster 1 | 0.33 | -0.52 | Versicolor | 62 |
| Cluster 2 | 1.72 | 0.20 | Virginica | 38 |
Interpretacion Detallada por Especie
Setosa (Cluster 0)
Caracteristicas Morfologicas:
- Petal Length: ~1.5 cm (muy pequeno)
- Petal Width: ~0.2 cm (muy pequeno)
- Sepal Width: ~3.4 cm (relativamente grande)
Posicion en PCA:
- Dim.1: Valores muy negativos (-2.68)
- Dim.2: Valores positivos (0.32)
Separabilidad:
Versicolor (Cluster 1)
Caracteristicas Morfologicas:
- Petal Length: ~4.3 cm (mediano)
- Petal Width: ~1.3 cm (mediano)
- Sepal Width: ~2.8 cm (mediano)
Posicion en PCA:
- Dim.1: Valores cercanos a 0 (0.33)
- Dim.2: Valores ligeramente negativos (-0.52)
Separabilidad:
Virginica (Cluster 2)
Caracteristicas Morfologicas:
- Petal Length: ~5.5 cm (grande)
- Petal Width: ~2.0 cm (grande)
- Sepal Width: ~3.0 cm (mediano)
Posicion en PCA:
- Dim.1: Valores muy positivos (1.72)
- Dim.2: Valores cercanos a 0 (0.20)
Separabilidad:
Por Que Versicolor y Virginica se Superponen?
Razones Biologicas
- Evolucion Compartida: Versicolor y Virginica son especies evolutivamente mas cercanas que Setosa
- Caracteristicas Similares: Ambas tienen petalos de tamano mediano-grande con rangos superpuestos
- Variabilidad Natural: Existe variabilidad natural dentro de cada especie que causa superposicion
Razones Estadisticas
- Rangos Superpuestos: Las medidas de petalo de Versicolor y Virginica tienen rangos que se superponen
- Distribuciones Gaussianas: Las distribuciones de ambas especies se solapan en las colas
- Limites Difusos: No existe una frontera clara en el espacio de 4 dimensiones
Visualizacion de la Separacion
En el espacio 2D del PCA, podemos ver claramente:
- Setosa: Grupo compacto en la esquina inferior izquierda (Dim.1 negativo)
- Versicolor: Grupo central (Dim.1 cercano a 0, Dim.2 negativo)
- Virginica: Grupo en la derecha (Dim.1 positivo), con superposicion con Versicolor
Validacion del Metodo No Supervisado
- Las especies tienen diferencias morfologicas reales y medibles
- El PCA captura correctamente la estructura de los datos
- K-Means es efectivo para este tipo de datos
- La superposicion Versicolor-Virginica es natural, no un error del algoritmo
Conclusiones y Recomendaciones
Conclusiones Principales
- Reduce de 4D a 2D manteniendo 96% de la informacion
- Las 2 primeras dimensiones son suficientes para visualizacion y clustering
- La perdida de solo 4% de informacion es insignificante
- Petal Length y Petal Width son las variables mas discriminantes
- Dim.1 (que representa el tamano del petalo) explica 73% de la varianza
- Para clasificacion de Iris, enfocarse en medidas de petalo es optimo
- Identifica correctamente las 3 especies en 89.3% de los casos
- Setosa es perfectamente separable (100%)
- La superposicion Versicolor-Virginica es natural y esperada
- Sin conocer las etiquetas, K-Means descubre los 3 grupos naturales
- Esto valida que las especies tienen diferencias morfologicas reales
- El metodo es robusto y confiable para este tipo de datos
Lecciones para Estudiantes
Leccion 1: La Importancia de la Reduccion de Dimensionalidad
ANTES DE PCA: 4 variables -> Dificil de visualizar -> Dificil de interpretar
DESPUES DE PCA: 2 dimensiones -> Facil de visualizar -> Patrones claros
Leccion 2: El Clustering No Supervisado Puede Descubrir Estructura Real
SIN ETIQUETAS: K-Means encuentra 3 grupos
CON ETIQUETAS: Hay 3 especies reales
COINCIDENCIA: 89.3%
Leccion 3: No Todos los Grupos son Perfectamente Separables
Setosa: 100% separable
Versicolor/Virginica: Superposicion natural (28% de error en Virginica)
Leccion 4: Validar, Validar, Validar
Metodo del Codo: Sugiere K=3
Silhouette Score: Confirma K=3
Pureza: Valida que K=3 es correcto (89.3%)
Recomendaciones Practicas
Para Clasificacion de Especies de Iris:
- Enfocarse en medidas de petalo (son las mas discriminantes)
- Usar PCA para visualizacion (reduce complejidad sin perder informacion)
- K=3 es optimo (validado por multiples metricas)
- Considerar la superposicion natural entre Versicolor y Virginica
Para Analisis de Datos Similares:
- Siempre hacer EDA primero (entender distribuciones y correlaciones)
- Estandarizar antes de PCA (variables en diferentes escalas sesgan resultados)
- Validar numero de clusters (no asumir K, usar Elbow + Silhouette)
- Comparar con ground truth (si esta disponible, como en este caso)
- Documentar decisiones (por que elegiste K=3, por que 2 dimensiones, etc.)
Extensiones Posibles
Otros Algoritmos de Clustering
- DBSCAN (clusters de forma arbitraria)
- Hierarchical Clustering (dendrogramas)
- Gaussian Mixture Models (probabilistico)
Clasificacion Supervisada
- Random Forest
- SVM (Support Vector Machines)
- Neural Networks
Analisis Adicionales
- LDA (Linear Discriminant Analysis)
- t-SNE (visualizacion no lineal)
- UMAP (reduccion de dimensionalidad)
Referencias Academicas
- Fisher, R. A. (1936). The use of multiple measurements in taxonomic problems. Annals of Eugenics, 7(2), 179-188.
- Anderson, E. (1935). The irises of the Gaspe Peninsula. Bulletin of the American Iris Society, 59, 2-5.
- Husson, F., Le, S., & Pages, J. (2017). Exploratory Multivariate Analysis by Example Using R. CRC Press.
- Pedregosa, F., et al. (2011). Scikit-learn: Machine Learning in Python. JMLR 12, pp. 2825-2830.